Skip to content
Deployment
Deployment Model Architecture
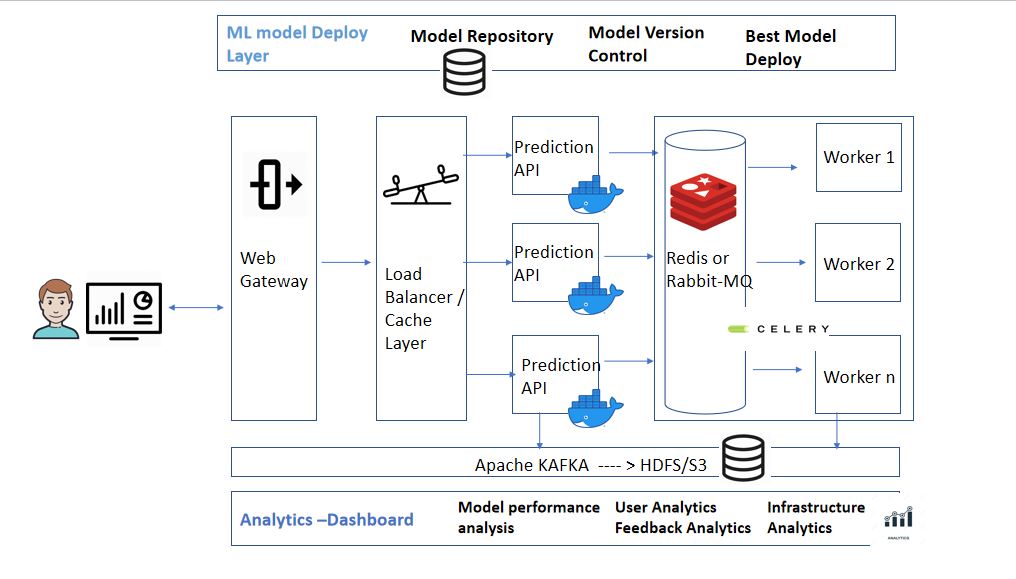
Deployment of the model APIs
since we want low-latency prediction we used async service instead of sync service
Here are APIs which can be deployed as part of this assignment
- Prediction API
- Feedback API
- Explanation API
- confidence Interval API
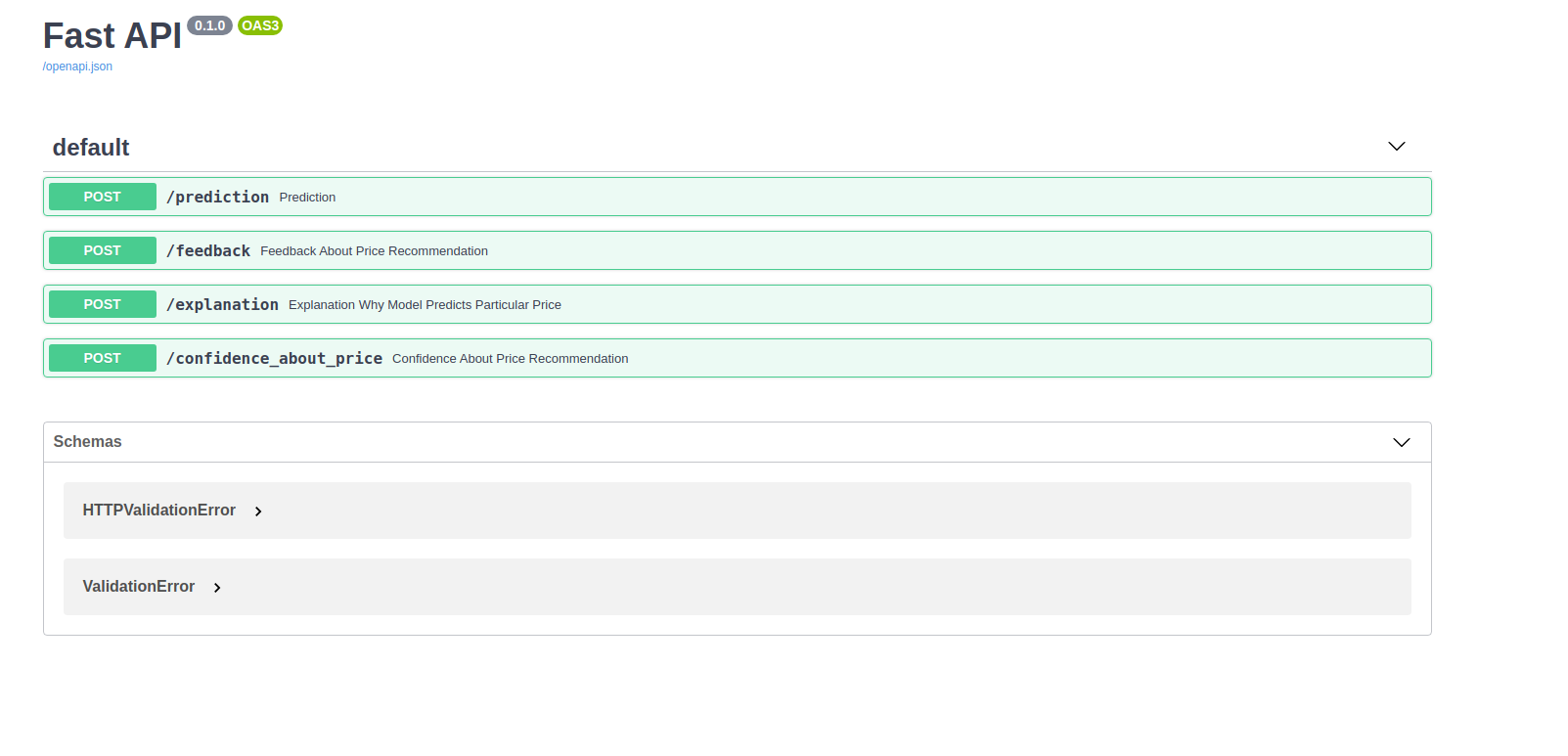
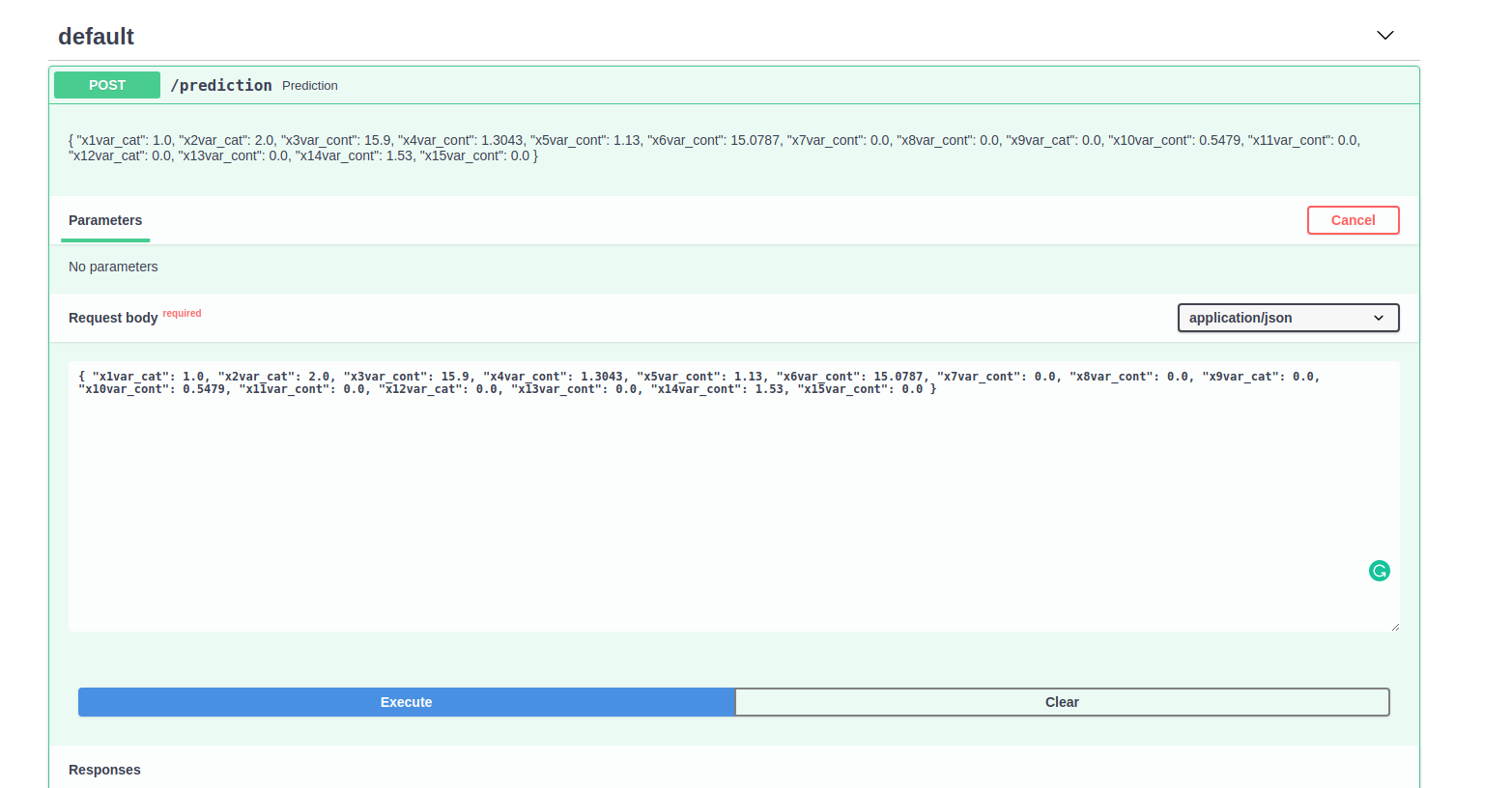
prediction API
- This is designed as a low latency async api
- This API expects
x1-x15 feature in a json format and returns a price recommendation
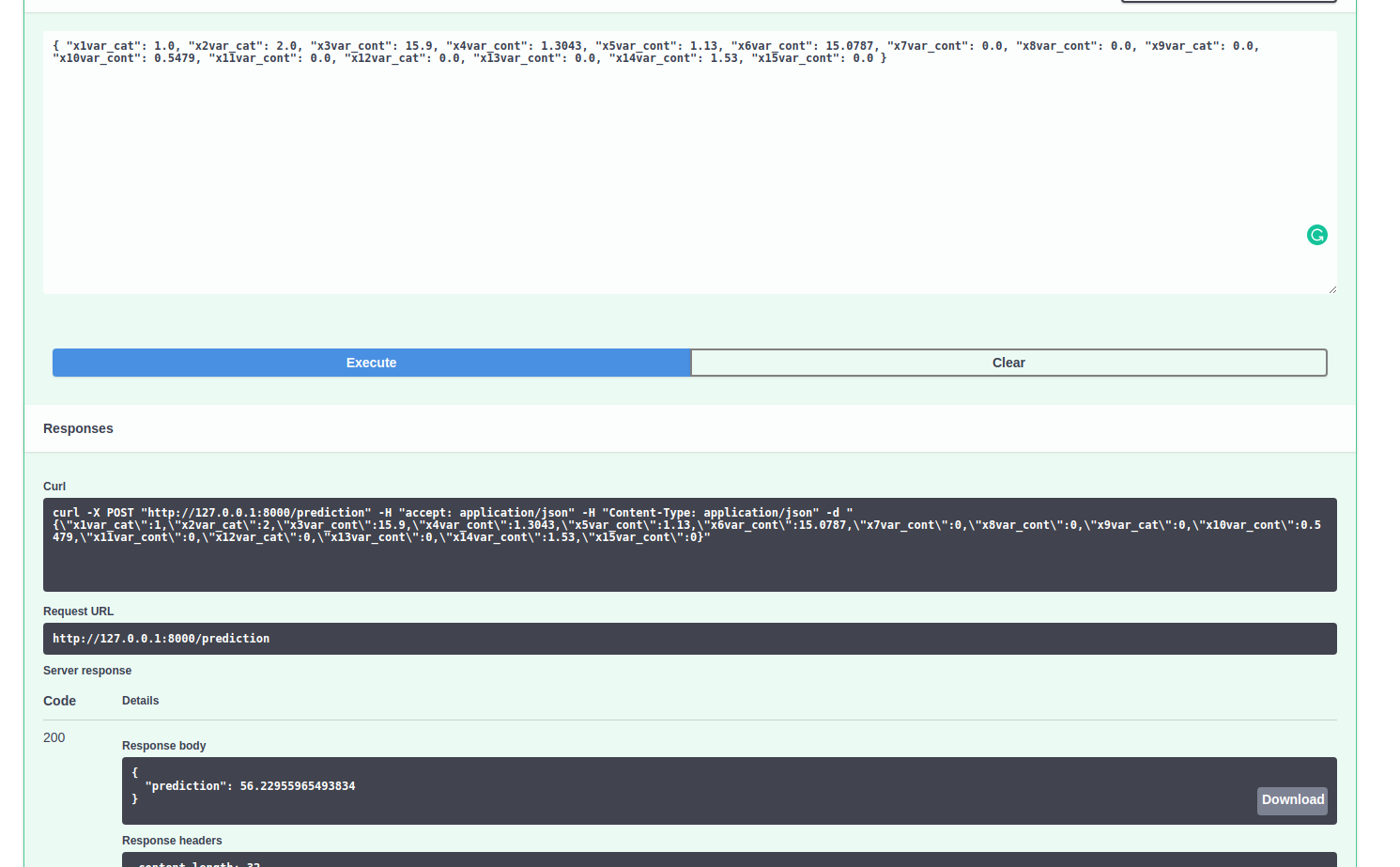
- Response shown in the below figure
Feedback API (NotImplemented)
- Where the feedback about the REcommended Price can be given by the user
Explanation (NotImplemented)
- Explanation for the every prediction why the model recommended particular value as prediction
Confidence Interval (NotImplemented)
- Instead predicting single price , if give exact price and range of the price it will be helpful to the user